|
我们都知道,在紫金桥软件中可以通过脚本或报表来访问关系库系统。我们通常的访问方式大概如下(以报表访问关系库为例):
- 建立报表关系数据源点,配置关系数据源点连接的数据库用户名和密码等属性。
- 绘制报表,在报表的关系数据库连接中指明第一步建立的报表关系数据源点。
- 在报表上写对关系库操作的命令,比如SELECT命令。
- 在报表中对关系库返回的结果进行处理,最简单的是报表自动显示结果。
这里第3步的SELECT命令中可以访问SQL中的表或视图。另外也可以使用存储过程,比如:
#R.SqlExeCmdNoRet("EXEC DOTRANCDATA");
这里的EXEC DOTRANCDATA表示执行DOTRANCDATA这个存储过程。
下面我们通过一个简单的例子来说明一下存储过程的用法。
比如我们需要做一个产品出入库的项目,产品在某一个地方通过驱动或条码设备自动进行入库操作,当数据进入关系库之后,可以通过关系库的各种统计分析查询功能来对产品进行统计和检索,由于需要在多个地方进行检索,所以SQL数据库放在远端网络的一个服务器上。
但是这里存在这么一个问题,由于网络有可能会偶尔出现故障,虽然在故障情况下暂时不能查询是可以理解的,但是我们不能允许在网络出现故障的情况下,产品不能入库。
这种问题可以这么解决,在本地关系库中建立一个缓冲表,数据先插入本地的缓冲表中,然后通过存储过程,把本地的缓冲表中的数据移动到远端的产品库中。在本地的任何检索和查询都是针对的远端的产品库来进行。这样当网络中断的时候,数据就可以先缓冲到本地,此时产品的入库工作仍然可以顺利的进行,只不过本地的数据无法自动的移动到远端,此时在远端的数据库中是无法检索到这些入库的产品的。当网络恢复之后,由存储过程自动的把数据移动到远端数据库中,此时在远端数据库中就可以检索到这些产品了。
下面我们举一个简单的例子,为了简化说明我们的两个表都在本地数据库中,首先数据插入其中的一个表中,然后在使用存储过程移动到另外一个表。对于跨数据库的表,处理方式一样,只需要稍微做些调整就行了。
首先我们在SQL中建立两个表,名为“测试数据源”和“测试目标”,如下图所示:
在测试数据源和测试目标中建立结构相同的两个数据表,如下图所示:
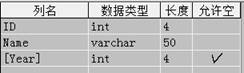
这里是一个简单的人员入库表,表明为User,有三个字段,第一个是自动增长的ID,第二个是人名,第三个年龄。
我们在紫金桥中创建一个关系数据源点,让该点连接“测试数据源”数据库,如下图所示:
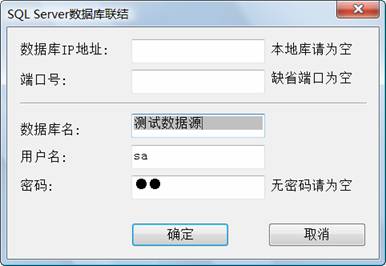
在紫金桥中创建一个窗口,并且创建一个报表,给报表关联刚刚建立的报表关系数据源点。
在报表上允许用户输入姓名和年龄,如下图所示:

给姓名和年龄的输入位置设置相应的输入方式,给提交按钮关联如下的脚本:
SqlExeCmdNoRet("INSERT INTO [User](Name, [Year]) VALUES ('"+Txt(1,1)+"', "+Txt(2,1)+")");
即可把人员姓名和年龄插入数据库中。
下面我们通过存储过程来把数据从“测试数据源”库移动到“测试目标”库中。
在“测试数据源”库中创建一个存储过程,如下图所示:
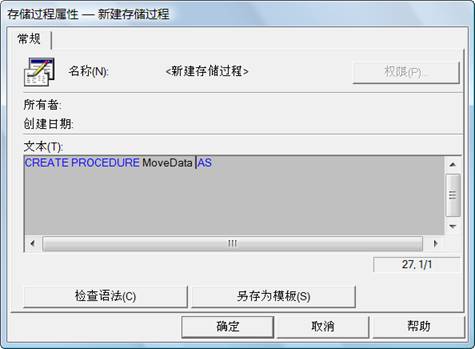
点击确定即可创建存储过程。
打开SQL查询分析器,选中相应的存储过程,右键菜单选择编辑功能,如下图所示:
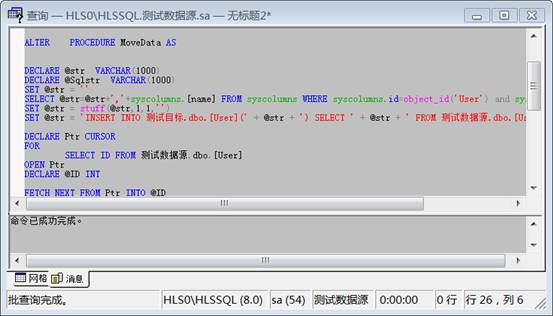
在此处输入如下的代码:
SET QUOTED_IDENTIFIER ON
GO
SET ANSI_NULLS OFF
GO
ALTERPROCEDURE MoveDataAS
DECLARE @strVARCHAR(1000)
DECLARE @SqlstrVARCHAR(1000)
SET @str = ''
SELECT @str=@str+','+syscolumns.[name] FROM syscolumns WHERE syscolumns.id=object_id('User') and syscolumns.[name]<>'ID'
SET @str = stuff(@str,1,1,'')
SET @str = 'INSERT INTO 测试目标.dbo.[User](' + @str + ') SELECT ' + @str + ' FROM 测试数据源.dbo.[User]'
DECLARE Ptr CURSOR
FOR
SELECT ID FROM 测试数据源.dbo.[User]
OPEN Ptr
DECLARE @ID INT
FETCH NEXT FROM Ptr INTO @ID
WHILE (@@FETCH_STATUS <> -1)
BEGIN
IF (@@FETCH_STATUS <> -2)
BEGIN
SET @Sqlstr = @str + ' WHERE ID=' + CONVERT(varchar, @ID)
EXEC(@Sqlstr)
DELETE FROM 测试数据源.dbo.[User] WHERE ID = @ID
END
FETCH NEXT FROM Ptr INTO @ID
END
CLOSE Ptr
DEALLOCATE Ptr
GO
SET QUOTED_IDENTIFIER OFF
GO
SET ANSI_NULLS ON
GO
其中前面和后面5行代码,是固定的,功能主要是更改存储过程的内容。
中间的内容是移动数据,这里我们不能简单的这样写:
INSERT INTO 测试目标.dbo.[User] SELECT * FROM 测试数据源.dbo.[User]
因为,两个表中都有自动增长的字段ID,如果复制所有的内容,也会导致复制ID字段的内容,而这会打乱系统自动增长的规律,可能会导致执行失败。
DECLARE @strVARCHAR(1000)
DECLARE @SqlstrVARCHAR(1000)
SET @str = ''
SELECT @str=@str+','+syscolumns.[name] FROM syscolumns WHERE syscolumns.id=object_id('User') and syscolumns.[name]<>'ID'
SET @str = stuff(@str,1,1,'')
这一段代码,查询User表中的所有名称不为ID的字段的名称,并用逗号分隔。
SET @str = stuff(@str,1,1,'')
这一句代码的功能是去除开始的逗号。
SET @str = 'INSERT INTO 测试目标.dbo.[User](' + @str + ') SELECT ' + @str + ' FROM 测试数据源.dbo.[User]'
这一句代码生成复制数据的命令。
DECLARE Ptr CURSOR
FOR
SELECT ID FROM 测试数据源.dbo.[User]
OPEN Ptr
DECLARE @ID INT
FETCH NEXT FROM Ptr INTO @ID
WHILE (@@FETCH_STATUS <> -1)
BEGIN
IF (@@FETCH_STATUS <> -2)
BEGIN
SET @Sqlstr = @str + ' WHERE ID=' + CONVERT(varchar, @ID)
EXEC(@Sqlstr)
DELETE FROM 测试数据源.dbo.[User] WHERE ID = @ID
END
FETCH NEXT FROM Ptr INTO @ID
END
CLOSE Ptr
DEALLOCATE Ptr
这一段代码,使用了多个游标,逐行的复制数据和删除数据,以实现移动数据的目的。
这里之所以采取一行一行的移动数据,主要是为了防止,在移动数据的过程中,又有了新的人员入库,插入了新的记录。一行一行的移动可以使得复制数据和删除数据可以一一对应。
最后可以把此存储过程放到作业中,使得它可以被周期运行,就可以实现自动的数据移动了。
|

