
银河通用机器人推出 LDA:全域数据、跨本体隐式世界-动作基座模型
http://www.gkong.com 2026-04-29 11:20 来源:银河通用机器人
在语言模型的发展历程中,GPT-2 之所以成为一个关键里程碑,并不只是因为模型本身能力的提升,更因为它第一次系统性地定义了一个问题——如何让模型有效利用互联网规模的异构数据。
从那一刻起,语言模型不再依赖少量高质量标注数据,而是开始以“全量数据”为燃料,进入持续 Scaling 的时代。
但在具身智能领域,这个问题从未被真正解决。
不同来源的数据彼此割裂:机器人数据与人类数据难以统一,真实与仿真难以融合,有动作标注与无动作视频难以协同,高质量与低质量数据往往被割裂使用。这些结构性的断层,使得具身智能始终停留在“数据稀缺驱动”的阶段,难以走向规模化学习。
近日,银河通用机器人发布的跨本体「隐式世界-动作基础模型」LDA,正是对这一问题的正面回答。
其核心突破不单在于模型能力的探索,而在于世界范围内首次在数据层面实现:虚实共融、人机混合、质量参差、有无动作标签的数据统一有效利用。
换句话说:一个模型,开始能够“吞吐全部数据,并让所有的数据各尽其用”。
这也意味着,具身智能第一次真正具备了类似 GPT-2 的能力——进入以数据规模驱动性能持续提升的新阶段。
具身数据范式新标准:从“筛选数据”到“组织数据”
在具身智能中,数据问题从来不是“有没有”,而是“能不能被统一利用”。
长期以来,不同类型的数据彼此割裂:真实机器人数据规模有限,遥操作数据成本高昂,人类视频缺乏动作标注,互联网数据难以对齐物理世界,而仿真数据又始终面临真实性约束。这使得具身智能始终依赖少量高质量数据驱动,难以走向规模化。
银河通用的解决方式,是构建完整的数据基础设施——银河星数(AstraData),并在 LDA 中实现对全类数据的统一完整运用。
围绕这一体系,银河通用构建了一个自下而上的数据结构(五层金字塔):
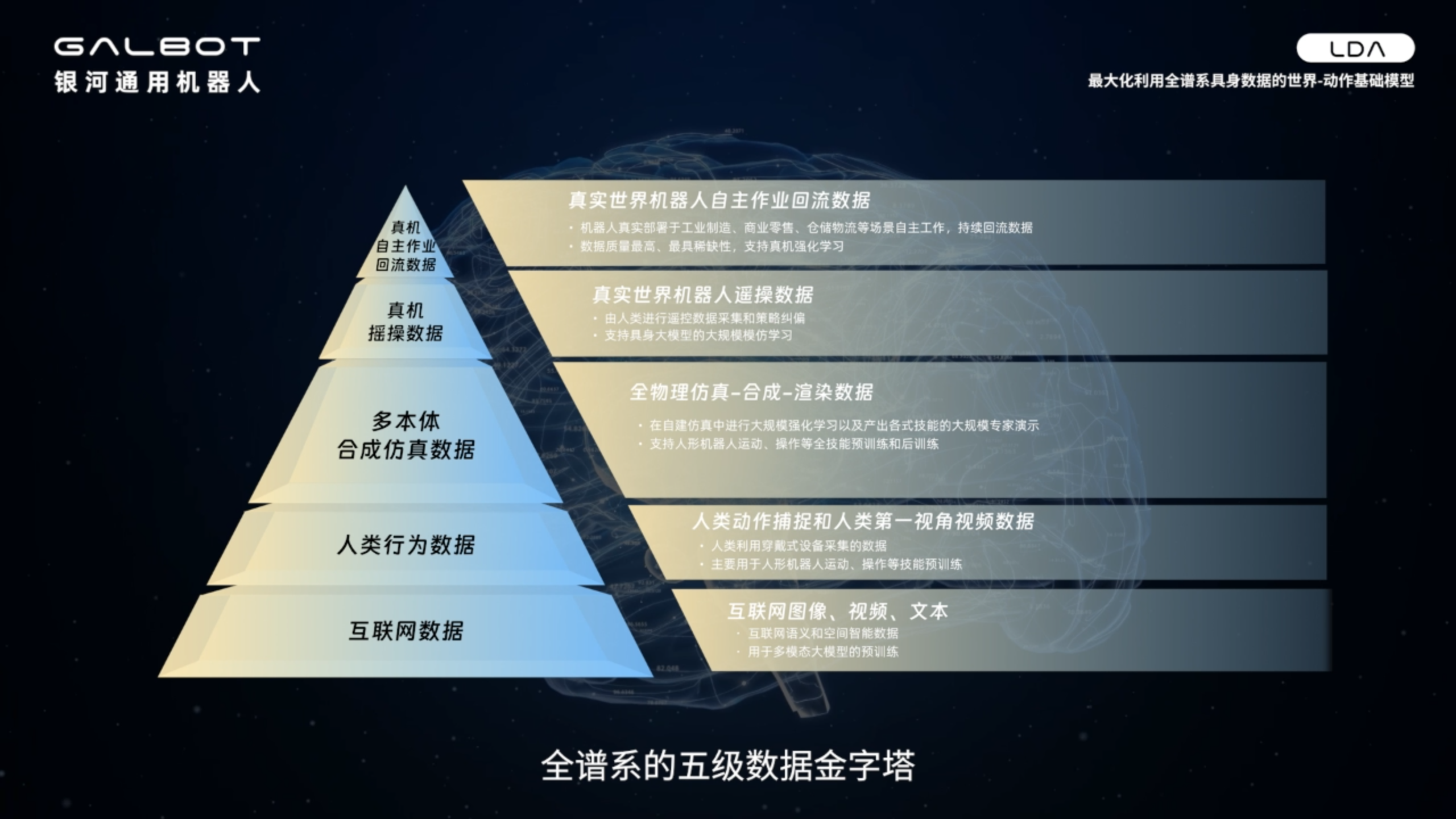
互联网图像/视频/文本数据(底层):规模最大、成本最低,用于构建基础感知与语义理解能力,但与具体动作执行相关性较弱
人类行为数据(次底层):提供动作先验与任务理解,将“视觉认知”连接到“行为语义”
多本体合成仿真数据(中间层,银河自研合成数据管线产出):以物理一致性为约束,大规模生成可控、多样的机器人交互数据,实现从认知到执行的关键过渡
真实遥操作数据(高层):提供高质量动作示范,但规模与采集效率受限
真实机器人自主运行数据(顶层):来自真实部署环境的闭环数据,直接反映系统在现实世界中的运行表现,并持续驱动强化学习与系统优化
高质量专家数据:同时用于策略与动力学建模,定义“最优动作”
低质量与噪声数据:用于前向与逆向动力学学习,刻画真实世界演化
无动作标注视频:用于视觉预测,提取行为结构与潜在意图
在这一框架下,数据不再被简单划分为“有用或无用”,而是被系统性重组进统一的世界-动作模型之中。
这一范式在 LDA 中首次展现出清晰的规模化特征:随着数据规模从数千小时扩展至数万小时,模型性能持续稳定提升。

尤其关键的是:即使引入大量低质量甚至失败数据,模型性能不降反升;在高质量动作数据耗尽后,仅依赖无动作标注的人类视频,模型依然可以持续进步。
这意味着,低质量数据与无动作数据,同样可以驱动具身模型的持续 Scaling——这一点,是传统行为克隆(BC)及既有世界模型方法难以实现的。
从这个角度看,LDA 不仅是一个模型突破,更是「银河星数」数据体系在模型层的关键闭环——标志着具身智能开始真正进入以数据驱动的规模化发展阶段。
具身模型范式统一:从 VLA, World Model 到 World Action Model
如果说数据决定模型能学什么,那么模型结构决定它如何理解这些数据。
传统机器人模型,本质上是从感知到动作的映射,其能力边界在于:它可以执行动作,但并不真正理解“动作之后世界会发生什么”。
LDA 在这一点上进行了根本性改变。
银河通用提出并实践的,是将 World Model(世界模型)与 Action Model(动作模型)统一的框架,即 WAM(World-Action Model)。
在模型层面,LDA 并不是一次结构创新,而是银河通用长期技术路线的自然延伸。
银河通用提出并实践的,是将World Model(世界模型)与Action Model(动作模型)统一的框架,即 WAM(World-Action Model)。
这一方向如今已成为具身智能领域的研究热点,但早在 2025 年 3 月,银河通用发表了 DyWA: Dynamics-adaptive World Action Model, 在全球范围内首次对 WAM 的概念进行结构化定义,并在接触动力学复杂的任务实现了成功的验证。
2025 年 3 月银河通用团队率先对 World-Action Model 展开前沿探索

在论文中,团队对 WAM 进行了系统性的定义
从这一时间节点来看,团队并非在跟随趋势,而是在这一关键范式尚未形成行业共识之前,就已经完成了前瞻研究。
也正是在这一技术路径的持续演进下,LDA 得以在同一模型中统一学习策略、动力学与视觉预测能力,形成真正闭环的“世界—行动”联合建模框架,使模型从“执行动作”走向“理解并作用于世界”。
在这一框架下,模型在同一体系中同时学习:
策略学习(Policy Learning):从当前观测生成动作
前向动力学(Forward Dynamics):预测动作将如何改变世界
逆向动力学(Inverse Dynamics):从结果反推中间行为
视觉预测(Visual Forecasting):在无动作条件下推演世界未来
这些能力不再彼此割裂,而是在同一表示空间与训练过程中协同优化,形成一个完整的“感知—决策—反馈”闭环。

这带来了以往模型难以实现的能力跃迁,换句话说,在「银河星脑」的整体架构中,LDA 让机器人第一次具备了这样一种能力:既能行动,也能理解行动如何改变世界。
这一步,使机器人从“执行任务的工具”,开始迈向“理解世界的系统”。
视觉表征统一和动作对齐:面向规模化的系统解法
World Action Model 类方法通常使用 VAE 派生的像素级表示进行动力学预测。这条路看似合理,却暗藏一个结构性缺陷:VAE 潜空间将外观、几何、动力学混杂在一起,不同机器人平台、不同光照场景的数据在这个空间里难以对齐,导致动力学学习受到严重干扰,更重要的是——难以随规模扩展持续收益。
论文数据直接说明了这一点:将 UWM 从 0.1B 扩展到 1B,RoboCasa-GR1 成功率仅从 14.2% 提升至 19.3%,即使替换为 MM-DiT 也只有 20.0%,Scaling 几乎停滞。
LDA 的核心选择,是放弃 VAE,转向 DINO 结构化潜空间。DINO 通过自监督预训练,天然过滤光照、纹理等外观冗余,保留物体级语义与空间结构。在这个空间中,不同机器人、不同环境的数据具有一致的表达形式——外观差异被压制,物理相关信息被突出,使跨本体的动力学学习真正成为可能。

而仅有视觉统一还远远不够,真正阻碍具身大模型扩展的另一堵墙,是动作空间的割裂。
不同机器人本体往往拥有完全不同的执行器形式:两指夹爪、多指灵巧手、吸盘、剪刀式末端执行器……如果仍然沿用各自独立的关节空间(joint space)建模,动作语义天然无法共享,数据规模再大,也只是分散在彼此孤立的数据孤岛中。
LDA 首次系统性地提出了一套统一的 hand-centric action space,将所有动作统一映射到“手如何作用于世界”这一物理本质上,而不是机器人自身的关节定义上。
具体来说,动作由两部分组成:
其一,是末端执行器的 delta wrist pose,即手腕在连续时刻之间的位姿变化(位置 + 姿态);这部分刻画的是操作意图本身,例如靠近、推拉、插入、翻转、对齐等跨本体共享的核心操作语义。
其二,是 finger configuration,即手部接触形态。对于 parallel-jaw gripper(平行夹爪),使用单自由度的 gripper width 表示开合状态;而对于 multi-finger dexterous hand(多指灵巧手),则使用在 wrist 坐标系下定义的关键点(keypoints)来描述手指构型,而非依赖不同本体各异的关节参数。
这一设计的关键突破在于:它不再让模型学习“某台机器人怎么动关节”,而是学习“手如何与物体发生作用”。
这意味着,夹取、旋转、插入、剪切这类操作,不再被绑定在某一种机械结构上,而能够在不同本体之间共享动力学规律。无论是仿真中的双指夹爪,还是真实世界中的多指灵巧手,模型看到的都是统一的物理交互语言。
超强真机表现:跨本体、少样本、长程灵巧操作
LDA 在真实世界中展现出强大的泛化与执行能力,模型在全部任务类别上稳定超越 GR00T-N1.6 和 π₀.₅,展现出更强的泛化与适应能力。
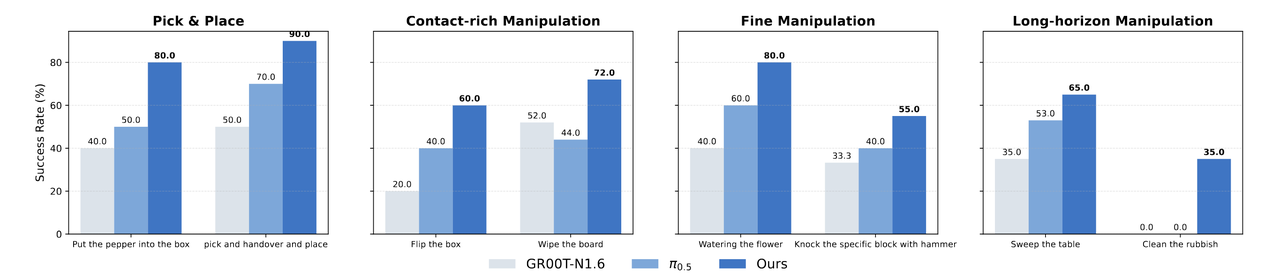
GROOT-N1.6、π0.5、LDA 三项工作在各类任务中使用二指夹爪操作的成功率对比
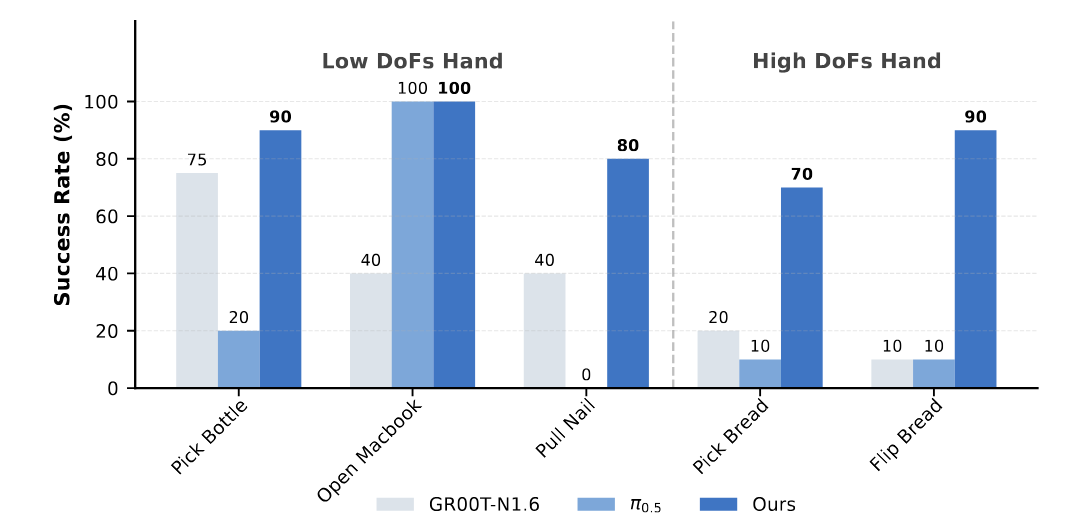
GROOT-N1.6、π0.5、LDA 三项工作在具体任务中使用灵巧手操作的成功率对比
少样本跨本体泛化
从工业场景中的物体搬运,到零售环境中的取放操作,再到家庭中的日常任务,LDA 能够在多种场景下稳定执行任务。

值得强调的是,所有测试所使用的机器人本体,均未出现在预训练数据中。
在这一严格设置下,在 Pick-and-Place 任务中进一步引入多种分布外扰动,包括未见位置、新物体以及背景变化。
结果表明,LDA 在各类扰动下仍能保持较高成功率,而仅依赖行为克隆(BC)的基线模型性能则出现显著下降。
这表明,LDA 学到的不只是“动作模仿”,而是能够跨本体迁移的世界-动作结构。
长程灵巧操作
在更具挑战性的长程任务与高自由度操作中,LDA 同样表现出色。例如,模型可以完成“煎牛排”“叠纸杯塔”等复杂操作,这类任务既需要长时序规划能力,也依赖精细的接触建模与控制能力。
在 LDA 驱动下,机器人可以胜任煎牛排这一长程任务,即便中途受到干扰(打断现有任务,发布新任务),机器人依然可以随机应变,按照指令理解并行动
失败数据让性能再提升
一个更具启发性的现象来自低质量真机数据。
在相同的数据设置下,将这部分包含大量失败和不稳定操作的数据加入训练: 对于 π₀.₅,性能明显下降;而对于 LDA,性能反而持续提升。
这表明,LDA 并不是简单依赖“干净数据”,而是能够从失败中学习世界的真实动力学,将原本被视为噪声的数据转化为有效信号。
具身基础模型进入“可规模化时代”
LDA 的突破,意味着具身智能的 scaling 路径正在发生根本性变化:它不再依赖稀缺而昂贵的专家示范数据作为唯一燃料,而是开始向更广泛、更真实、更复杂的数据来源全面打开——包括业务回流数据、低质量操作轨迹,以及大规模人类行为视频。
在这一范式下,数据不再被严格筛选为“可用”与“不可用”,而是被统一纳入模型对世界的建模过程之中。真正决定能力上限的,不再是数据是否完美,而是模型是否具备从异构数据中抽取结构、规律与因果关系的能力。
从这个角度看,LDA 回答的并不只是“如何构建一个更强的模型”,而是一个更基础的问题:机器人,是否可以像语言模型一样,从海量异构数据中持续学习世界本身?
而 LDA 给出的答案正在变得清晰:当动力学学习、策略学习与视觉预测被统一到同一表示空间,当低质量甚至失败数据也能转化为有效监督信号,具身智能就第一次具备了“从真实世界持续学习”的基础条件。
在这一进程中,银河通用将 LDA 的核心算法与代码体系全面开源,希望推动行业从封闭优化走向开放共建,加速基础能力的整体跃迁。
更重要的是,这一能力并非孤立存在,而是嵌入在「银河星脑(AstraBrain)」的完整技术体系之中:从「银河星坊」所构建的数据基础设施,到跨本体的世界-动作基础模型,再到面向真实场景的持续部署与反馈学习闭环,正在形成一条完整的具身智能技术管线。
接下来,这一体系将进一步向真实应用场景延展,从工业制造、零售服务,到复杂开放环境中的自主作业能力,推动具身智能从“可演示能力”,走向“可持续运行能力”,并最终成为新一代生产力基础设施的一部分。
编辑精选
工控原创
- ▪ 十年深耕国产测控,简仪科技发布AI时代新战略
- ▪ 5 月 RatingDog 中国通用制造业 PMI 为 51.8 通胀压力半年来首次缓解
- ▪ NVIDIA 和宇树科技宣布推出 H2 Plus 以推进人形机器人研究
- ▪ 2026 五月智造潮工业自动化月度盘点!
- ▪ 报告:物理AI发展提速,软件已成机器人创新最大瓶颈
- ▪ 乐聚智能创业板 IPO 获受理,拟募资 26 亿元
- ▪ 施耐德电气加入世界经济论坛灯塔运营系统顾问委员会,共推开源制造蓝图
- ▪ 摩根士丹利重磅报告:人形机器人将成中国出口新引擎
- ▪ 四月工业自动化领域动态全览!
- ▪ 汇川技术年营收首破 450 亿 新兴业务加速跑 一季度利润承压不改长期布局


